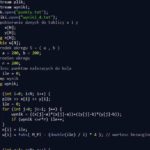
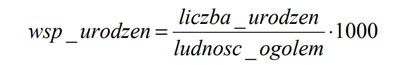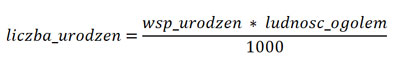Popularna gra: Zgadnij o jakiej liczbie myślę! Polega na tym, że komputer losuje liczbę z zakresu [0;100], a my musimy odgadnąć tę liczbę. Wynikiem jest po ilu razach została odgadnięta ta liczba.
C++
#include <iostream>
#include <time.h>
#include <stdlib.h>
#include <conio.h>
#include <cstdio>
#include <windows.h>
using namespace std;
int main()
{
char znak;
do {
system("cls");
srand(time(NULL));
int liczba=rand()%101;
int zgadywana_liczba;
int ile = 0;
do {
cout << "Zgadnij liczbe o jakiej mysle z przedzialu [0:100] : ";
cin >> zgadywana_liczba;
ile++;
if (zgadywana_liczba>liczba)
cout << "Podana liczba jest za duza." << endl;
if (zgadywana_liczba<liczba)
cout << "Podana liczba jest za mala." << endl;
} while (liczba!=zgadywana_liczba);
cout << "Brawo! Zgadles po " << ile << " razach!" << endl;
cout << endl << "Czy chcesz zgadywac jeszcze raz? [T/N]";
cin >> znak;
} while (toupper(znak)!='N');
return 0;
}
JAVA
import java.util.Random;
import java.util.Scanner;
public class ZgadujZgadula {
public static void main(String[] args) {
// stworzenie obiektu klasy random
Random losowanie = new Random();
// losowanie liczby z zakresu [0;100] i przypsianie do zmiennej całkowitej
int los = losowanie.nextInt(101);
int liczba = 101;
int i=0;
do {
i++;
System.out.println("Podaj liczbę o jakiej myślę.");
Scanner wej = new Scanner(System.in);
liczba = wej.nextInt();
if (los == liczba)
System.out.println("To jest zgadywana liczba.");
else if (los > liczba)
System.out.println("Podana liczba jest za mała.");
else
System.out.println("Podana liczba jest za duża.");
} while (los != liczba);
// wyswietlenie tej losowej liczby
System.out.println("Zgadłeś po "+i+" razach.");
}
}
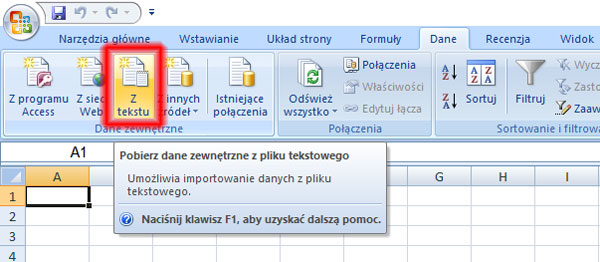
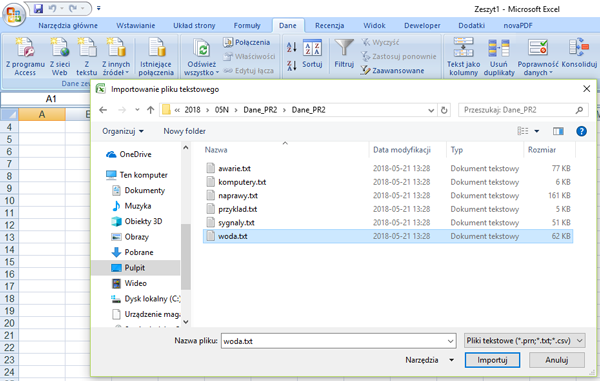
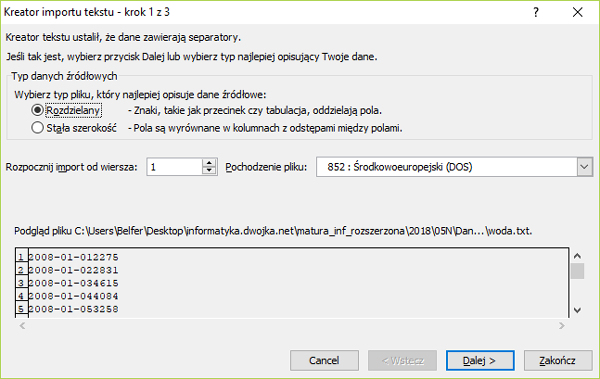
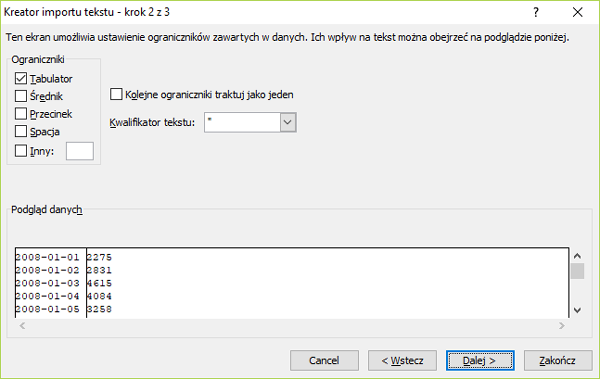
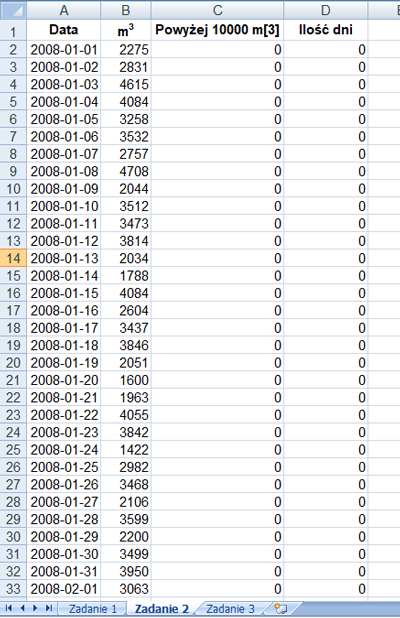
Rzeka Wirka co roku wylewała. Aby temu zapobiec, wybudowano na rzece zbiornik retencyjny. W kolejnych wierszach pliku woda.txt znajdują się dane dotyczące dziennego dopływu wody z rzeki Wirki do zbiornika retencyjnego w kolejnych dniach z lat 2008–2017. Plik zawiera 3 653 wiersze. W każdym wierszu podane są dane: data (rrrr-mm-dd) oraz liczba metrów sześciennych wody, jaka dopływała do zbiornika w ciągu doby. Dane oddzielone są znakami tabulacji.
Za pomocą dostępnych narzędzi informatycznych podaj odpowiedzi do poniższych zadań. Odpowiedzi zapisz w pliku wyniki.txt, a każdą odpowiedź poprzedź numerem odpowiedniego zadania.
Krok 6. Wskazanie miejsca gdzie ma importować dane.
Zadanie 1.
Podaj rok, w którym zbiornik retencyjny został zasilony łącznie największą liczbą metrów sześciennych wody z rzeki Wirki.
Rozwiązanie:
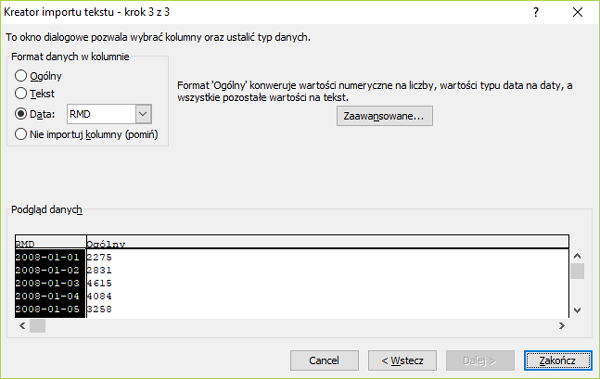
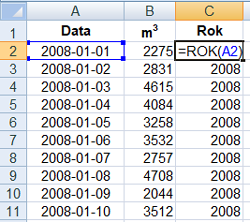
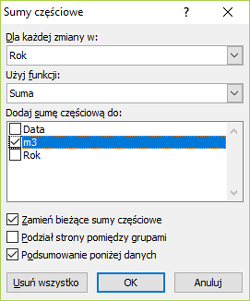
Rozpocząć musimy od wybrania roku z daty za pomocą funkcji =ROK(A2).
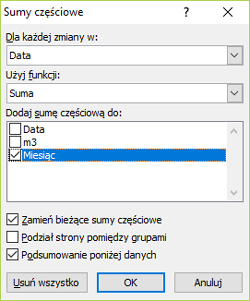
Do uzyskania odpowiedzi wykorzystamy sum częściowych.
Wybieramy sumy częściowe ze wstążki Dane.
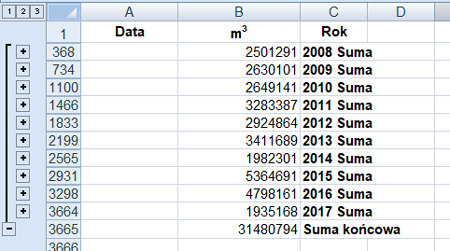
W ustawieniach sum częściowych wybieramy Rok, Suma dla pola m3. Po wykonaniu sum mamy wynik, suma wszystkich metrów sześciennych dla każdego roku.
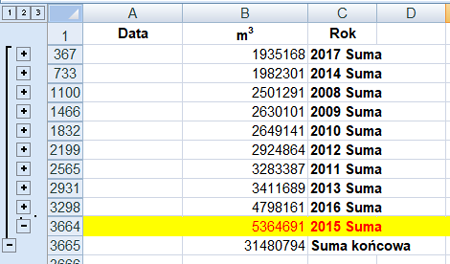
Do wybrania roku w którym największą liczbą metrów został zasilony zbiornik retencyjny wykorzystamy sortowanie A-Z (lub Z-A).
Odpowiedź:
Rok 2015 – 5364691 m3
Zadanie 2.
Jaki był najdłuższy okres liczony w dniach, w którym codziennie dopływało do zbiornika retencyjnego co najmniej 10 000 metrów sześciennych wody z rzeki Wirki? Jest tylko jeden taki okres. Podaj datę początkową i datę końcową tego okresu.
Rozwiązanie:
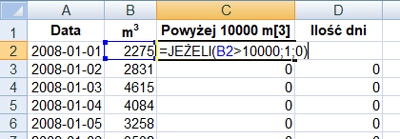
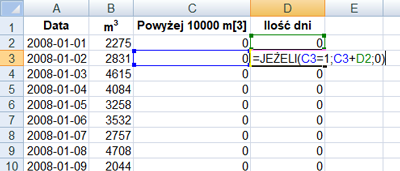
Do obliczenia ilości dni proponuje wykonać następujące czynności. Po pierwsze sprawdzamy którego dnia powyżej 10000 m3 wody dopływa do zbiornika z rzeki. Jeżeli jest tak, należy obliczyć ile dni pod kolei spełnia ten warunek.
Po wykonaniu funkcji: =jeżeli(B2>10000;1;0) i =jeżeli(C3=1;C3+D2;0) należy sprawdzić jaki okres był najdłuższy oraz możemy sprawdzić daty od kiedy to było.
Odpowiedź:
Ilość takich dni to: 55. Pierwsza data to: 2015-03-17. Ostatnia data to: 2015-05-10.
Zadanie 3.
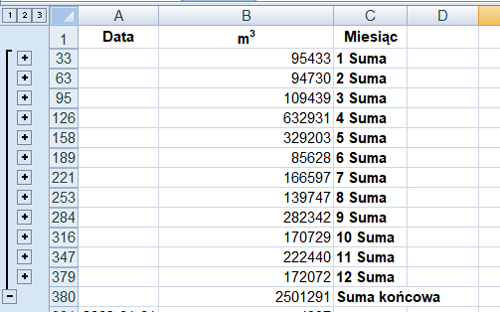
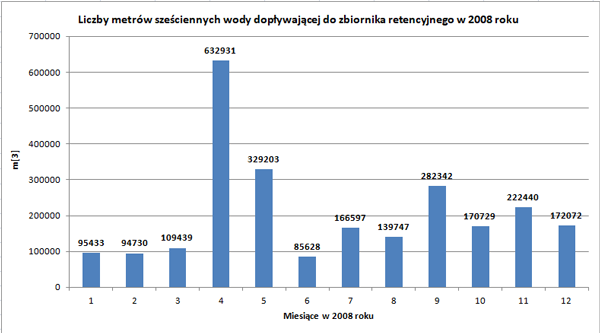
Utwórz i podaj zestawienie łącznej liczby metrów sześciennych wody dopływającej do zbiornika retencyjnego w kolejnych miesiącach 2008 roku (od stycznia 2008 do grudnia 2008). Na podstawie zestawienia wykonaj wykres kolumnowy. Pamiętaj o czytelnym opisie wykresu (tytuł wykresu i opisy osi).
Rozwiązanie:
Przed rozpoczęciem obliczenia należy wybrać z daty nr miesiąca w 2008 roku za pomocą funkcji =MIESIĄC(A2). Następnie do uzyskania odpowiedzi wykorzystam sumy częściowe dla zaznaczonego obszaru m3 i wybrany miesiąc z daty (tylko 2008 rok).
Należy utworzyć wykres dla danych:
Odpowiedź:
m[3]
Miesiąc
95433
1
94730
2
109439
3
632931
4
329203
5
85628
6
166597
7
139747
8
282342
9
170729
10
222440
11
172072
12
Zadanie 4.
Poniżej opisano cykl pracy zbiornika retencyjnego.
1) Na początku doby, zaraz po północy, wykonywany jest pomiar objętości wody w zbiorniku i na jego podstawie realizuje się pozostałe działania.
2) Jeśli pomiar wskazuje w zbiorniku więcej niż 1 000 000 m3 wody, to nastąpiło tzw. przepełnienie zbiornika. W takiej sytuacji, niezwłocznie po wykonaniu pomiaru i stwierdzeniu przepełnienia, nadmiar wody powyżej 1 000 000 m3 jest wypuszczany ze zbiornika.
3) Codziennie rano (o godzinie 8) ze zbiornika wypuszcza się 2% objętości wody wykazanej przez pomiar zaraz po północy. Ilość wypuszczanej wody zaokrągla się w górę do pełnych metrów sześciennych.
Uwaga: pomiar wykonany po północy 2008-02-01 wskazał 338 406 m3 wody.
Uwzględnij opisany cykl pracy zbiornika retencyjnego oraz codzienne dopływy wody z Wirki i przyjmij, że pomiar w dniu 2008-01-01 wskazywał 500 000 m3 wody, a następnie:
a) podaj dzień, w którym pierwszy raz wypuszczono nadmiar wody po przepełnieniu,
b) podaj, w ilu dniach z podanego okresu (tj. od 2008-01-01 do 2017-12-31) w zbiorniku w momencie pomiaru znajdowało się co najmniej 800 000 m3 wody,
c) podaj, ile najwięcej wody znalazłoby się w podanym okresie (tj. od 2008-01-01 do 2017-12-31) w zbiorniku (w momencie pomiaru), gdyby całkowicie zrezygnować z procedury wypuszczania nadmiaru wody powyżej 1 000 000 m3, a zbiornik miałby nieograniczoną pojemność.
Rozwiązanie:
Pkt. a)
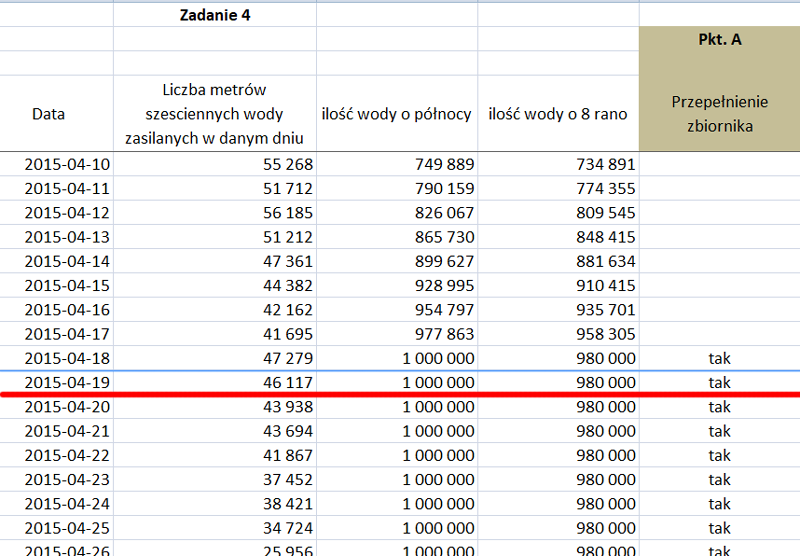
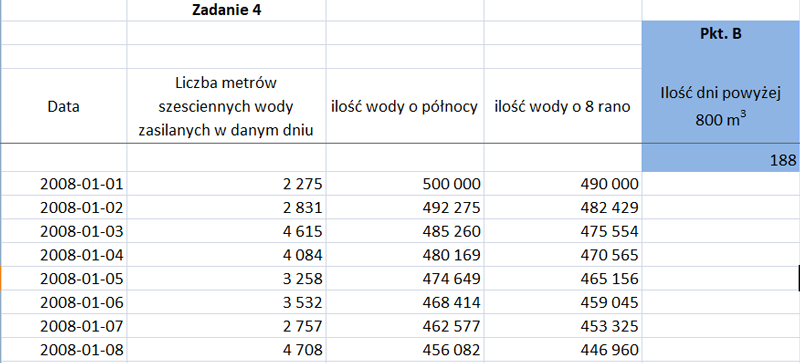
Do wykonania punktu należy sprawdzić poprzez utworzenie tabeli z danymi takimi jak na rysunku:
Wykonałem formułę zliczającą ilość wody każdego dnia o północy poprzez policzenie w kolumnie pomocniczej ilość wody o 8 rano, ponieważ każdego dnia rano jest wylewane 2% objętości całkowitej wody.
W kolumnie ilość wody o północy znajduje się formuła:
=JEŻELI(D6+B6>1000000;1000000;D6+B6)
Musiałem wykonać funkcję jeżeli do sprawdzenia czy ilość wody w zbiorniku o północy nie przekracza 1 000 000 m3. Jeżeli przekroczyła ilość wody 1 000 000 m3 to musimy zmniejszyć ilość wody do 1 000 000 m3.
Odpowiedź zaznaczona została na czerwono, ponieważ jest pytanie: Którego dnia pierwszy raz wypuszczono nadmiar wody po przepełnieniu? Wydawać się może, że jest to dzień wcześniej, ale jest błędna odpowiedź, ponieważ tego dnia było równo 1 000 000 m3 wody w zbiorniku, zaś wylano wodę ze zbiornika 2015-04-19. W kolumnie przepełnienie zbiornika wykorzystałem funkcję:
=JEŻELI(C8>=1000000;”tak”;””)
Odpowiedź:
pkt. a) 2015-04-19
Rozwiązanie:
Pkt. b)
To zadanie należy obliczyć wykorzystując funkcję, która policzy nam ilość komórek zawierających 800 000 m3 lub więcej w danym dniu:
=LICZ.JEŻELI(C6:C3658;”>=800000″)
Odpowiedź:
pkt. b) 188
Rozwiązanie:
Pkt. c)
Punkt c w tym zadaniu wykonać należy za pomocą funkcji już wcześniej wykorzystanej licząc ilość wody w zbiorniku, tylko należy usunąć funkcję obniżająca ilość wody w zbiorniku, kiedy przekroczy 1 000 000 m3. Następnie wybrać należy największa wartość za pomocą funkcji MAX.
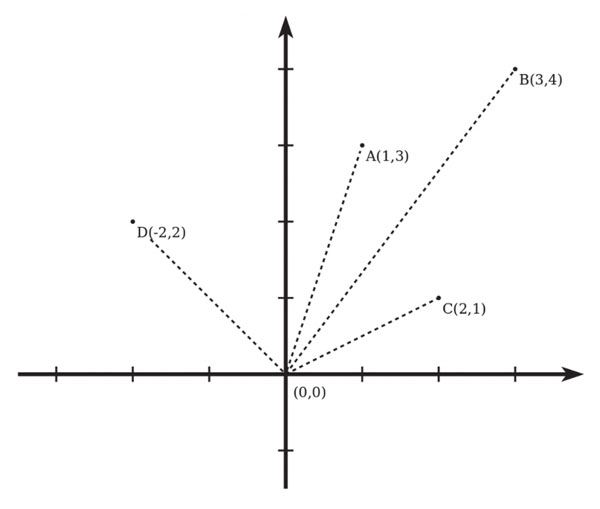
W pewnym paśmie górskim znajduje się n szczytów, które będziemy przedstawiać jako punkty w układzie kartezjańskim na płaszczyźnie. Wszystkie punkty leżą powyżej osi OX, tzn. druga współrzędna (y) każdego punktu jest dodatnia.
W punkcie (0,0) stoi obserwator. Jeśli dwa szczyty A i B mają współrzędne (xA, yA) oraz (xB, yB), to mówimy, że:
• szczyt A jest dla obserwatora widoczny na lewo od B, jeśli xA/yA < xB/yB;
• szczyt B jest widoczny na lewo od A, jeśli xA/yA > xB/yB.
Wiemy, że żadne dwa szczyty nie leżą w jednej linii z obserwatorem, a zatem dla obserwatora te szczyty nie zasłaniają się nawzajem. Ilustrację przykładowego położenia szczytów można zobaczyć na poniższym rysunku:
W tym przykładzie, patrząc od lewej do prawej strony, obserwator widzi kolejno szczyt D, szczyt A, szczyt B i szczyt C.
Współrzędne szczytów dane są w dwóch tablicach X[1..n] oraz Y[1..n] – szczyt numer i ma współrzędne (X[i], Y[i]).
Zadanie 1.
Napisz algorytm (w pseudokodzie lub wybranym języku programowania), który znajdzie i poda współrzędne skrajnie lewego szczytu, tzn. widocznego dla obserwatora na lewo od wszystkich pozostałych szczytów.
Specyfikacja:
Dane:
n – liczba całkowita dodatnia
X[1..n] – tablica liczb całkowitych
Y[1..n] – tablica liczb całkowitych dodatnich
Para (X[i], Y[i]) to współrzędne jednego szczytu, i = 1, 2, …, n.
Żadne dwa szczyty nie leżą w jednej linii z obserwatorem.
Wynik:
x, y – współrzędne skrajnie lewego szczytu spośród tych opisanych w tablicach X i Y.
Algorytm:
#include <iostream>
using namespace std;
int main()
{
int n=4;
int X[n]={1,3,2,-2};
int Y[n]={3,4,1,2};
int x,y;
for (int i=0; i<n-1; i++)
if (float(X[i])/float(Y[i]) < float(X[i+1])/float(Y[i+1])) {
x = X[i];
y = Y[i];
}
cout << x << " " << y << endl;
return 0;
}
Zadanie 2.
Napisz algorytm (w pseudokodzie lub wybranym języku programowania), który przestawi elementy tablic X i Y tak, aby szczyty były uporządkowane w kolejności, w której obserwator widzi je od lewej do prawej strony. Aby otrzymać maksymalną ocenę, Twój algorytm powinien mieć złożoność czasową kwadratową lub mniejszą. Algorytm może używać wyłącznie instrukcji sterujących, operatorów arytmetycznych, operatorów logicznych, porównań i przypisań do zmiennych. Zabronione jest używanie funkcji bibliotecznych dostępnych w językach programowania.
Specyfikacja:
Dane:
n – liczba całkowita dodatnia
X[1..n] – tablica liczb całkowitych
Y[1..n] – tablica liczb całkowitych dodatnich
Para (X[i], Y[i]) to współrzędne jednego szczytu, i = 1, 2, …, n.
Żadne dwa szczyty nie leżą w jednej linii z obserwatorem.
Wynik:
X[1..n], Y[1..n] – tablice zawierające współrzędne danych szczytów, uporządkowanych w kolejności, w której obserwator widzi je od lewej do prawej strony.
Algorytm:
#include <iostream>
using namespace std;
int main()
{
int n=4;
int X[n]={1,3,2,-2};
int Y[n]={3,4,1,2};
for (int j=0; j<n-1; j++)
for (int i=0; i<n-1; i++) {
if (float(X[i])/float(Y[i]) > float(X[i+1])/float(Y[i+1])) {
swap(X[i],X[i+1]);
swap(Y[i],Y[i+1]);
}
}
for (int i=0; i<n; i++) {
cout << "X[" << i << "]= " << X[i] << " ";
cout << "Y[" << i << "]= " << Y[i];
cout << endl;
}
return 0;
}
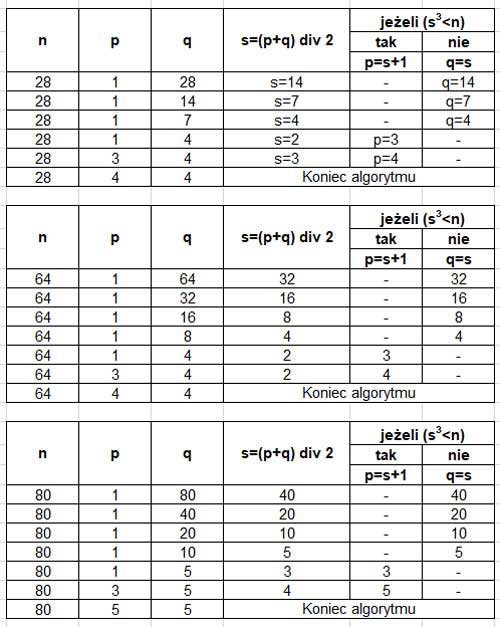
p ← 1
q ← n
dopóki p < q wykonuj
s ← (p+q) div 2
(*) jeżeli s*s*s < n wykonaj
p ← s+1
w przeciwnym wypadku
q ← s
Uwaga: zapis div oznacza dzielenie całkowite.
Zadanie 1.
Podaj wynik działania algorytmu dla wskazanych w tabeli wartości n.
n
p
28
4
64
4
80
5
Miejsce na obliczenia.
Algorytm:
#include <iostream>
using namespace std;
int main()
{
cout << "Podaj n = ";
int n, p=1;
cin >> n;
int q=n;
int s;
while (p<q) {
s = (p+q)/2;
if (s*s*s<n)
p=s+1;
else
q=s;
}
cout << "p = " << p << endl;
return 0;
}
Zadanie 2.
Podaj najmniejszą oraz największą liczbę n, dla której wynikiem działania algorytmu będzie p = 10.
Miejsce na obliczenia.
Najmniejsza liczba n to 9*9*9+1=730, ponieważ musi być spełniony warunek s3<n. Największa liczba n to 10*10*10=1000, ponieważ musi być spełniony warunek s3<n.
Odpowiedź: Najmniejsza liczba to 730, największa liczba to 1000.
Zadanie 3.
Dokończ zdanie. Wybierz i zaznacz właściwą odpowiedź spośród podanych. Dla każdej liczby całkowitej n > 1 instrukcja oznaczona w algorytmie symbolem (*) wykona się
A. mniej niż 2*log2n razy.
B. więcej niż n/2, ale mniej niż n razy.
C. więcej niż n+1, ale mniej niż 2n razy.
D. więcej niż n2 razy.
Komentarz:
Odpowiedź A ponieważ, 2*log2n -> 2 * log264 = 2 * 6 = 12. Jest to mniej niż 12.
Podaj, ile liczb zapisanych w pliku dane_6.txt to liczby pierwsze.
Rozwiązanie:
#include <iostream>
#include <fstream>
#define N 2000
using namespace std;
bool liczba_pierwsza(int a) {
int i=2;
bool wynik = true;
while (a>i) {
if (a%i==0) {
wynik = false;
break;
}
i++;
}
return wynik;
}
int main()
{
int tab[N];
int ile=0;
ifstream plik;
plik.open("dane4.txt");
for (int i=0; i<N; i++){
plik >> tab[i];
if (liczba_pierwsza(tab[i]))
ile++;
}
cout << ile << endl;;
plik.close();
ofstream wynik;
wynik.open("wynik_6.txt");
wynik << "Liczb pierwszych jest : " << ile;
wynik.close();
return 0;
}
Zadanie 2.
Podaj, jaka jest największa oraz jaka jest najmniejsza liczba pierwsza z pliku dane_6.txt.
Rozwiązanie:
#include <iostream>
#include <fstream>
#define N 2000
using namespace std;
bool liczba_pierwsza(int a) {
int i=2;
bool wynik = true;
while (a>i) {
if (a%i==0) {
wynik = false;
break;
}
i++;
}
return wynik;
}
int main()
{
int tab[N];
int maksimum=0, minimum=30000;
ifstream plik;
plik.open("dane4.txt");
for (int i=0; i<N; i++){
plik >> tab[i];
if (liczba_pierwsza(tab[i])) {
if (tab[i]>maksimum)
maksimum=tab[i];
if (tab[i]<minimum)
minimum=tab[i];
}
}
cout << maksimum << endl;
cout << minimum << endl;
plik.close();
ofstream wynik;
wynik.open("wynik_6.txt");
wynik << "Maksymalana liczba pierwsza jest to : " << maksimum << endl;
wynik << "Minimalna liczba pierwsza jest to : " << minimum;
wynik.close();
return 0;
}
Zadanie 3.
Liczby bliźniacze to takie dwie liczby pierwsze, które różnią się o 2, np.: (3, 5), (5, 3), (11, 13) lub (19, 17).
Zbadaj w pliku dane_6.txt kolejne pary sąsiadujących ze sobą liczby, tzn. pierwszą i drugą liczbę, drugą i trzecią liczbę, …, przedostatnią i ostatnią liczbę. Podaj liczbę par liczb bliźniaczych oraz wypisz wszystkie te pary. Każdą parę wypisz w osobnym wierszu.
Przykład:
Dla poniższych danych
11698
13234
1999
1997
16444
15173
5927
odpowiedzią jest:
1
1999 i 1997.
Rozwiązanie:
#include <iostream>
#include <fstream>
#define N 2000
using namespace std;
bool liczba_pierwsza(int a) {
int i=2;
bool wynik = true;
while (a>i) {
if (a%i==0) {
wynik = false;
break;
}
i++;
}
return wynik;
}
int main()
{
int tab[N];
ifstream plik;
plik.open("dane4.txt");
for (int i=0; i<N; i++){
plik >> tab[i];
}
plik.close();
ofstream wynik;
int w=0;
wynik.open("wynik_6.txt");
for (int i=0; i<N-1; i++)
if (liczba_pierwsza(tab[i]) && liczba_pierwsza(tab[i+1]))
if ((tab[i]==tab[i+1]+2) || (tab[i]==tab[i+1]-2)) {
w++;
wynik << tab[i] << " " << tab[i+1] << endl;
}
wynik << w;
wynik.close();
return 0;
}
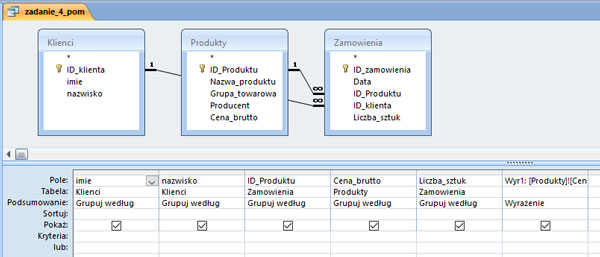
Sklep internetowy Matrix zajmuje się sprzedażą sprzętu komputerowego. W plikach produkty.txt, klienci.txt oraz zamowienia.txt znajdują się dane dotyczące działalności sklepu w okresie od maja 2012 roku do maja 2013 roku włącznie. W każdym pliku pierwszy wiersz jest wierszem nagłówkowym.
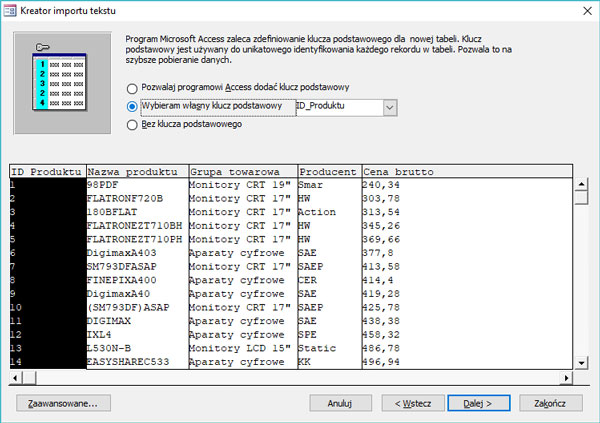
Plik produkty.txt zawiera zestawienie dostępnych produktów – identyfikator produktu, nazwę produktu, grupę towarową, producenta i cenę brutto.
Fragment pliku produkty.txt:
ID_Produktu
Nazwa_produktu
Grupa_towarowa
Producent
Cena_brutto
1
98PDF
Monitory CRT 19″
Smar
240,34
8
FINEPIXA400
Aparaty cyfrowe
CER
414,4
446
EXPRESSP1-J224Y
Notebooki
HW
5350,52
Plik klienci.txt zawiera dane osób składających zamówienia – identyfikator klienta, imię i nazwisko.
Fragment pliku klienci.txt:
ID_klienta
imie
nazwisko
TL518
Tymoteusz
Legierski
AZ877
Anna
Zakopianska
AB721
Antoni
Borek
Plik zamowienia.txt zawiera następujące informacje: identyfikator zamówienia, datę zamówienia, identyfikator zamawianego produktu, identyfikator klienta, który złożył zamówienie, oraz liczbę sztuk zamówionego produktu.
Fragment pliku zamowienia.txt:
ID_zamowienia
Data
ID_Produktu
ID_klienta
Liczba_sztuk
1/2012
2012-05-14
405
TC563
1
2/2012
2012-05-15
417
HS605
1
3/2012
2012-05-16
180
JP555
1
Wykorzystując dane zawarte w tych plikach oraz dostępne narzędzia informatyczne, wykonaj podane polecenia. Odpowiedzi zapisz w pliku wyniki_5.txt, poprzedzając je numerami zadań.
Pobieranie danych do programu. Zadanie zostało rozwiązane za pomocą MS Access.
Krok 1. Pobieranie danych zapisanych w plikach tekstowych do aplikacji.
Krok 2. Wybór pliku do pobrania.
Krok 3. Kreator pobierania danych z pliku do tabeli.
Krok 4.
Krok 5. Sprawdzenie czy pobierane dane są odpowiedniego typu.
Krok 6. Wybór klucza podstawowego dla pola w tabeli.
Krok 7.
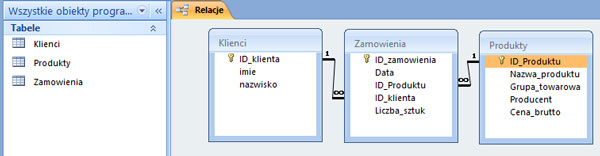
Krok 8. Tworzenie relacji.
Zadanie 1.
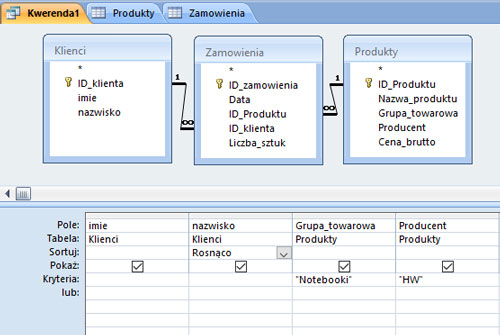
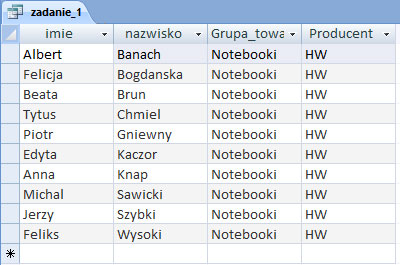
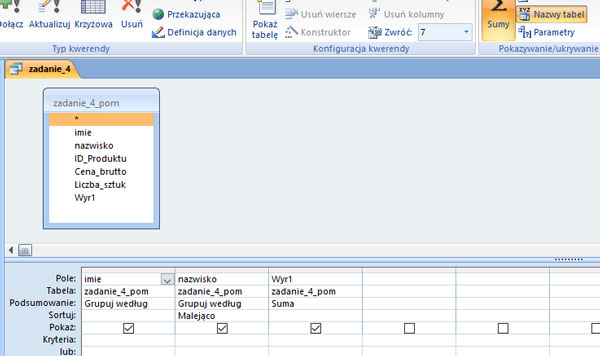
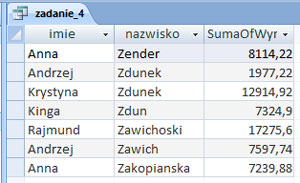
Podaj imiona i nazwiska wszystkich osób, które zakupiły notebooki firmy HW. Nazwiska posortuj alfabetycznie.
Rozwiązanie:
Zadanie 2.
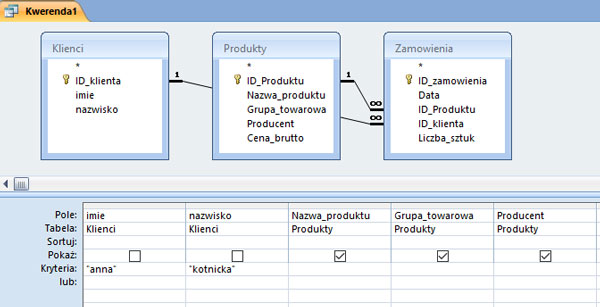
Podaj nazwy produktów zakupionych przez klienta Anna Kotnicka, grupy towarowe oraz producentów tych produktów.
Rozwiązanie:
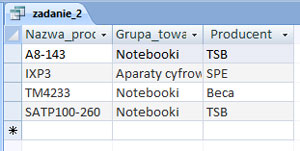
Zadanie 3.
Podaj imię i nazwisko osoby, która złożyła największą liczbę zamówień w sklepie internetowym Matrix, oraz liczbę tych zamówień.
Rozwiązanie:
Zadanie 4.
Podaj imiona i nazwiska trzech osób, które zapłaciły za wszystkie zamówione przez siebie towary najwięcej spośród wszystkich klientów. Zwróć uwagę, że klient mógł zamówić w jednym zamówieniu kilka sztuk tego samego produktu.
Rozwiązanie:
Zadanie 5.
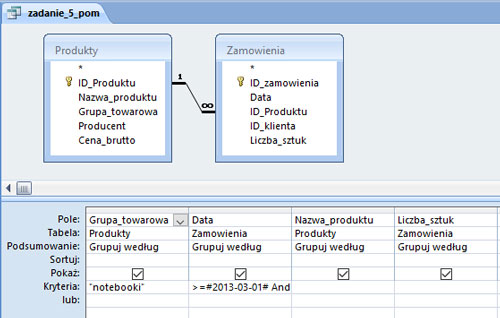
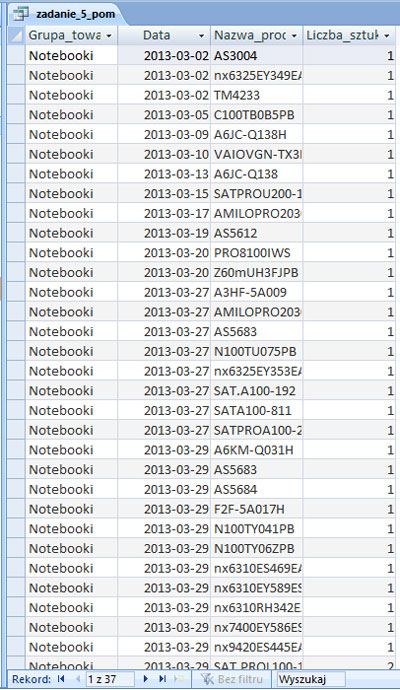
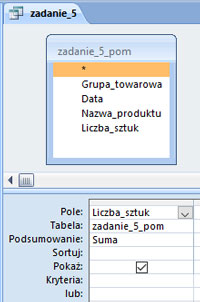
Podaj, ile notebooków zamówiono w marcu 2013 roku.
W pliku demografia.txt znajdują się informacje o urodzeniach, zgonach i ruchu naturalnym ludności w Polsce w roku 2009, w podziale na województwa i powiaty. Pierwszy wiersz w pliku jest wierszem nagłówkowym.
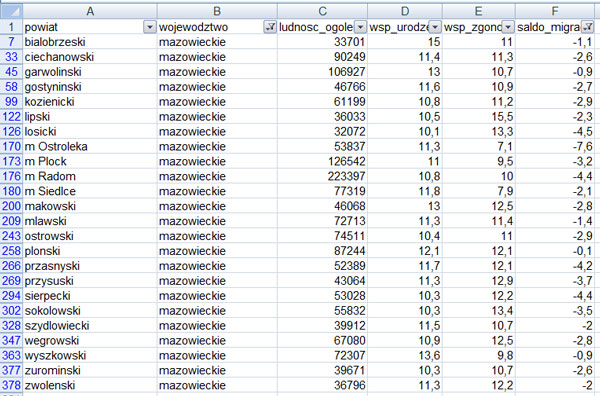
Fragment pliku demografia.txt:
powiat
wojewodztwo
ludnosc_ogolem
wsp_urodzen
wsp_zgonow
saldo_migracji
augustowski
podlaskie
58763
10,4
10,5
-1,1
bedzinski
slaskie
150950
9,4
13
3,1
belchatowski
lodzkie
112993
11,5
9,1
-1,6
Korzystając z dostępnych narzędzi informatycznych oraz danych zawartych w pliku demografia.txt, wykonaj podane polecenia. Odpowiedź do każdego zadania poprzedź numerem tego zadania.
Pobieranie danych do programu.
Zadanie 1.
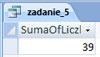
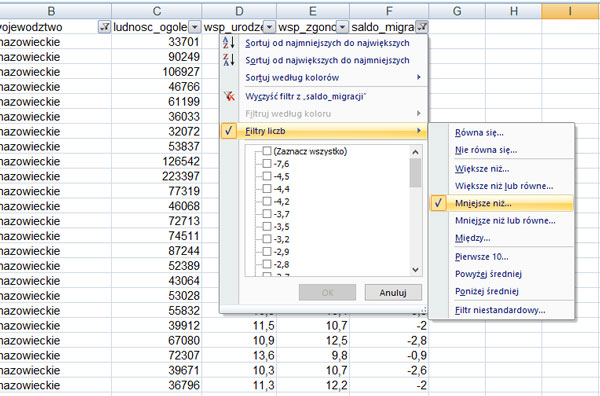
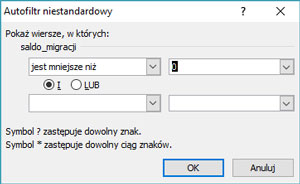
Podaj liczbę powiatów należących do województwa mazowieckiego, w których saldo migracji było ujemne.
Rozwiązanie:
Komentarz:
Do obliczenia ilości powiatów z województwa mazowieckiego, których saldo migracji jest ujemne należy użyć filtra dla województwa – ustalamy mazowieckie, zaś dla kolumny saldo_migracji używamy filtra liczb -> mniejsza niż -> ustalamy wartość na 0 (zero). Ilość wyświetlonych wierszy jest równa 24.
Zadanie 2.
Współczynnik przyrostu naturalnego to różnica pomiędzy współczynnikiem urodzeń a współczynnikiem zgonów. Utwórz zestawienie 10 powiatów o największym współczynniku przyrostu naturalnego zawierające nazwę powiatu i współczynnik przyrostu naturalnego. Zestawienie uporządkuj alfabetycznie.
Rozwiązanie:
Komentarz:
Współczynnik przyrostu naturalnego obliczamy w nowej kolumnie G wykorzystując funkcję =D2-E2. Następnie sortujemy Z-A wg kolumny G. Następnie ukrywamy kolumny od B-F, a potem sortujemy wg powiatu tylko pierwszych dziesięć powiatów.
Zadanie 3.
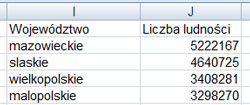
Podaj nazwy czterech województw o największej liczbie ludności oraz liczbę ludności w tych województwach.
Rozwiązanie:
Komentarz:
W pierwszej kolejności należy wybrać wszystkie występujące województwa w naszym zestawieniu. Kolejnym krokiem jest obliczanie ilości mieszkańców dla każdego województwa, wykonujemy to za pomocą funkcji:
=SUMA.JEŻELI($B$2:$B$380;I2;$C$2:$C$380)
Zakres komórek z których sumujemy to wszystkie nazwy województw $B$2:$B$380, zaś suma to liczba mieszkańców w każdym powiecie należącym do województwa $C$2:$C$380. W funkcji tej występuję jeszcze I2, jest to nazwa województwa wpisana wcześniej. Sortujemy malejąco wg ilości sumy mieszkańców w danym województwie. Wybieramy pierwsze cztery rekordy.
Zadanie 4.
Współczynnik urodzeń to liczba urodzeń na 1000 mieszkańców, czyli:
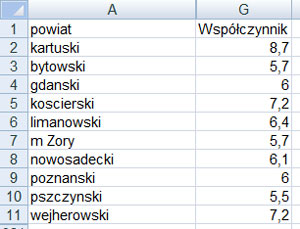
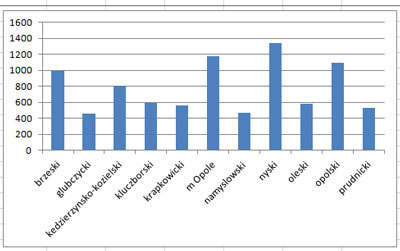
Na podstawie podanej liczby ludności każdego powiatu (ludność ogółem) oraz współczynnika urodzeń w tym powiecie wykonaj dla województwa opolskiego zestawienie powiatów oraz liczby urodzeń w 2009 roku w każdym powiecie. Obliczoną liczbę urodzeń zaokrąglij w dół do najbliższej liczby całkowitej. Zestawienie posortuj alfabetycznie. Na podstawie powyższego zestawienia utwórz wykres kolumnowy ilustrujący liczbę urodzonych dzieci w poszczególnych powiatach. Pamiętaj o prawidłowym opisie wykresu.
Rozwiązanie:
Komentarz:
Rozwiązywanie zadania należy rozpocząć od wykonania sortowania wg województw, ponieważ musimy wykonać tylko dla województwa opolskiego. Następnie dla nowej kolumny tworzymy formułę odwrotną obliczającą liczbę urodzeń ze wzoru:
dzięki przekształceniu wzoru została utworzona formuła: =ZAOKR.DÓŁ(D180*C180/1000;0)
Na zakończenie tworzymy wykres z danych: nazwy powiatu województwa opolskiego i danych z kolumny G.
Dowolną liczbę n ∈ N można zapisać za pomocą sumy: sumy jej cyfr i iloczynu pewnego współczynnika k oraz liczby 9, gdzie k ∈ N .
Przykłady:
19 = 1 + 9 + (1 * 9)
123 = 1 + 2 + 3 + (13 * 9)
Zadanie 1.
Uzupełnij tabelę – wpisz dla podanej liczby n jej rozkład i współczynnik k.
n
Rozkład liczby
k
11
1 + 1 + ( k * 9 ) = 2 + 1 * 9
1
42
4 + 2 + ( k * 9 ) = 6 + 4 * 9
4
375
3 + 7 + 5 + ( k * 9 ) = 15 + 40 * 9
40
913
9 + 1 + 3 + ( k * 9 ) = 13 + 100 * 9
100
Obliczenia:
Wykonujemy sumowanie poszczególnych cyfr podanej liczby n. Następnie mamy liczbę z jedną niewiadomą. Ogólny wzór to:
Sc + k * 9 = n
k = ( n – Sc ) / 9
gdzie k – szukany współczynnik, n – liczba, Sc – suma cyfr składających się na liczbę n.
n= 42
k = ( 42 – 6 ) / 9 = 4
Zadanie 2.
Zapisz algorytm w wybranej przez siebie notacji obliczający sumę cyfr w zapisie dziesiętnym danej liczby n ∈ N . W zapisie algorytmu możesz korzystać tylko z następujących operacji arytmetycznych: dodawania, odejmowania, mnożenia, dzielenia całkowitego i obliczania reszty z dzielenia.
Specyfikacja:
Dane:
n ∈ N
Wynik:
s – suma cyfr liczby n
Algorytm:
#include <iostream>
using namespace std;
int main()
{
int n = 913;
int suma=0;
while (n>0) {
suma=suma+n%10;
n=n/10;
}
cout << suma << endl;
return 0;
}
Zadanie 3.
Zapisz algorytm w wybranej przez siebie notacji, który oblicza współczynnik k dla n ∈ N. W zapisie algorytmu możesz korzystać tylko z następujących operacji arytmetycznych: dodawania, odejmowania, mnożenia, dzielenia całkowitego i obliczania reszty z dzielenia. Możesz również zastosować funkcję suma_cyfr(n) obliczającą sumę cyfr liczby n.
Specyfikacja:
Dane:
n ∈ N
Wynik:
współczynnik k w rozkładzie liczby n
Algorytm:
#include <iostream>
using namespace std;
int Sc(int n) {
int suma=0;
while (n>0) {
suma=suma+n%10;
n=n/10;
}
return suma;
}
int main()
{
int n = 3;
cout << "k= " << (n-Sc(n))/9 << endl;
return 0;
}
Rozważmy algorytm kompresji, który zlicza liczbę kolejnych wystąpień tego samego znaku, a następnie zamiast całej grupy identycznych znaków podaje ten znak tylko jeden raz, poprzedzając go liczbą jego kolejnych wystąpień. Liczba kolejnych wystąpień każdego znaku nie przekracza 9, więc do zapisania tej liczby wystarczy jeden znak.
Przykład:
tekst źródłowy
tekst skompresowany
rozmiar tekstu w liczbie znaków
źródłowego
skompresowanego
FFFYYYYYYYYYFFFHAAAAA
3F9Y3F1H5A
21
10
Zadanie 1.
Skompresuj powyższym algorytmem tekst podany w tabeli, oblicz rozmiar tekstu przed kompresją i po kompresji.
tekst źródłowy
tekst skompresowany
rozmiar tekstu w liczbie znaków
źródłowego
skompresowanego
***##!!*
3*2#2!1*
8
8
Zadanie 2.
Ile powinna wynosić minimalna liczba kolejnych znaków w grupie, aby jej kompresja była opłacalna?
Rozwiązanie:
W tekście musi występować powyżej dwa takie same znaki lub minimum dwa razy występować trzy takie same znaki.
Zadanie 3.
Czy opisana metoda kompresji jest stratna, czy – bezstratna?
Rozwiązanie:
Opisana kompresja jest bezstratna, ponieważ tekst, który został skompresowany, możliwe jest przywrócić tekst źródłowy bez jakiejkolwiek straty.
Zadanie 4.
Napisz (w postaci listy kroków, schematu blokowego, pseudokodu lub w wybranym języku programowania) algorytm obliczający rozmiar skompresowanego tekstu.
Specyfikacja:
Dane:
n – dodatnia liczba całkowita, długość kompresowanego tekstu
T[1..n] – tablica zawierająca tekst do skompresowania; T[i] – i-ty znak w tekście
Wynik:
b – rozmiar skompresowanego tekstu T
Algorytm:
#include <iostream>
using namespace std;
int main()
{
string tekst = "***##!!*";
string nowy = "";
int dl = tekst.length();
int ile=1;
char szyfr = tekst[0];
for (int i=1; i<dl; i++){
if(szyfr==tekst[i])
ile++;
else {
nowy+=(48+ile);
nowy+=szyfr;
ile=1;
szyfr = tekst[i];
}
}
nowy+=(48+ile);
nowy+=szyfr;
cout << nowy.length();
return 0;
}